#apache kafka on aws
Explore tagged Tumblr posts
Visit Tumblr Blog
Explore Tumblr blogs with no restrictions, modern design and the best experience.
Last Seen Tumblr Blogs





Fun Fact
12.7% of mobile users access Tumblr.
Text
Real-Time Data Streaming: How Apache Kafka is Changing the Game
Introduction
In today’s fast-paced digital world, real-time data streaming has become more essential than ever because businesses now rely on instant data processing to make data-driven and informed decision-making. Apache Kafka, i.e., a distributed streaming platform for handling data in real time, is at the heart of this revolution. Whether you are an Apache Kafka developer or exploring Apache Kafka on AWS, this emerging technology can change the game of managing data streams. Let’s dive deep and understand how exactly Apache Kafka is changing the game.
Rise of Real-Time Data Streaming
The vast amount of data with businesses in the modern world has created a need for systems to process and analyze as it is produced. This amount of data has emerged due to the interconnections of business with other devices like social media, IoT, and cloud computing. Real-time data streaming enables businesses to use that data to unlock vast business opportunities and act accordingly.
However, traditional methods fall short here and are no longer sufficient for organizations that need real-time data insights for data-driven decision-making. Real-time data streaming requires a continuous flow of data from sources to the final destinations, allowing systems to analyze that information in less than milliseconds and generate data-driven patterns. However, building a scalable, reliable, and efficient real-time data streaming system is no small feat. This is where Apache Kafka comes into play.
About Apache Kafka
Apache Kafka is an open-source distributed event streaming platform that can handle large real-time data volumes. It is an open-source platform developed by the Apache Software Foundation. LinkedIn initially introduced the platform; later, in 2011, it became open-source.
Apache Kafka creates data pipelines and systems to manage massive volumes of data. It is designed to manage low-latency, high-throughput data streams. Kafka allows for the injection, processing, and storage of real-time data in a scalable and fault-tolerant way.
Kafka uses a publish-subscribe method in which:
Data (events/messages) are published to Kafka topics by producers.
Consumers read and process data from these subjects.
The servers that oversee Kafka's message dissemination are known as brokers.
ZooKeeper facilitates the management of Kafka's leader election and cluster metadata.
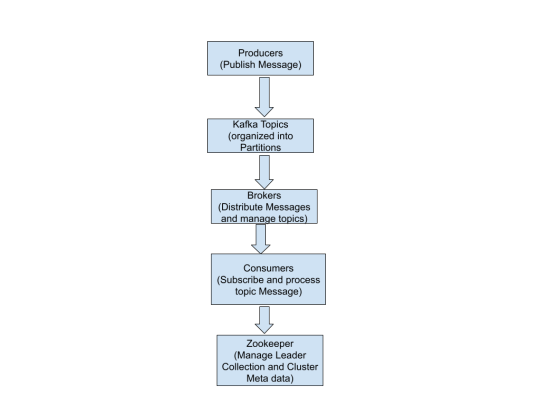
With its distributed architecture, fault tolerance, and scalability, Kafka is a reliable backbone for real-time data streaming and event-driven applications, ensuring seamless data flow across systems.
Why Apache Kafka Is A Game Changer
Real-time data processing helps organizations collect, process, and even deliver the data as it is generated while immediately ensuring the utmost insights and actions. Let’s understand the reasons why Kafka stands out in the competitive business world:
Real-Time Data Processing
Organizations generate vast amounts of data due to their interconnection with social media, IoT, the cloud, and more. This has raised the need for systems and tools that can react instantly and provide timely results. Kafka is a game-changer in this regard. It helps organizations use that data to track user behavior and take action accordingly.
Scalability and Fault Tolerance
Kafka's distributed architecture guarantees data availability and dependability even in the case of network or hardware failures. It is a reliable solution for mission-critical applications because it ensures data durability and recovery through replication and persistent storage.
Easy Integration
Kafka seamlessly connects with a variety of systems, such as databases, analytics platforms, and cloud services. Its ability to integrate effortlessly with these tools makes it an ideal solution for constructing sophisticated data pipelines.
Less Costly Solution
Kafka helps in reducing the cost of data processing and analyzing efficiently and ensures high performance of the businesses. By handling large volumes of data, Kafka also enhances scalability and reliability across distributed systems.
Apache Kafka on AWS: Unlocking Cloud Potential
Using Apache Kafka on ASW has recently become more popular because of the cloud’s advantages, like scalability, flexibility, and cost efficiency. Here, Kafka can be deployed in a number of ways, such as:
Amazon MSK (Managed Streaming for Apache Kafka): A fully managed service helps to make the deployment and management of Kafka very easy. Additionally, it handles infrastructure provisioning, scaling, and even maintenance and allows Apache Kafka developers to focus on building applications.
Self-Managed Kafka on EC2: This is apt for organizations that prefer full control of their Kafka clusters, as AWS EC2 provides the flexibility to deploy and manage Kafka instances.
The benefits of Apache Kafka on ASW are as follows:
Easy scaling of Kafka clusters as per the demand.
Ensures high availability and enables disaster recovery
Less costly because it uses a pay-as-you-go pricing model
The Future of Apache Kafka
Kafka’s role in the technology ecosystem will definitely grow with the increase in the demand for real-time data processing. Innovations like Kafka Streams and Kafka Connect are already expanding the role of Kafka and making real-time processing quite easy. Moreover, integrations with cloud platforms like AWS continuously drive the industry to adopt Kafka within different industries and expand its role.
Conclusion
Apache Kafka is continuously revolutionizing the organizations of modern times that are handling real-time data streaming and changing the actual game of businesses around the world by providing capabilities like flexibility, scalability, and seamless integration. Whether you are deploying Apache Kafka on AWS or working as an Apache Kafka developer, this technology can offer enormous possibilities for innovation in the digitally enabled business landscape.
Do you want to harness the full potential of your Apache Kafka systems? Look no further than Ksolves, where a team of seasoned Apache Kafka experts and developers stands out as a leading Apache Kafka development company with their client-centric approach and a commitment to excellence. With our extensive experience and expertise, we specialize in offering top-notch solutions tailored to your needs.
Do not let your data streams go untapped. Partner with leading partners like Ksolves today!
Visit Ksolves and get started!
#kafka apache#apache kafka on aws#apache kafka developer#apache cassandra consulting#certified developer for apache kafka
0 notes
Text
AWS MSK Create & List Topics
Problem I needed to created topics in Amazon Web Services(AWS) Managed Streaming for Apache Kafka(MSK) and I wanted to list out the topics after they were created to verify. Solution This solution is written in python using the confluent-kafka package. It connects to the Kafka cluster and adds the new topics. Then it prints out all of the topics for verification This file contains…

View On WordPress
#amazon web services#apache kafka#aws#confluent-kafka#create#kafka#kafka topic#list#managed streaming for apache kafka#msk#python#topic
0 notes
Text
How can you optimize the performance of machine learning models in the cloud?
Optimizing machine learning models in the cloud involves several strategies to enhance performance and efficiency. Here’s a detailed approach:

Choose the Right Cloud Services:
Managed ML Services:
Use managed services like AWS SageMaker, Google AI Platform, or Azure Machine Learning, which offer built-in tools for training, tuning, and deploying models.
Auto-scaling:
Enable auto-scaling features to adjust resources based on demand, which helps manage costs and performance.
Optimize Data Handling:
Data Storage:
Use scalable cloud storage solutions like Amazon S3, Google Cloud Storage, or Azure Blob Storage for storing large datasets efficiently.
Data Pipeline:
Implement efficient data pipelines with tools like Apache Kafka or AWS Glue to manage and process large volumes of data.
Select Appropriate Computational Resources:
Instance Types:
Choose the right instance types based on your model’s requirements. For example, use GPU or TPU instances for deep learning tasks to accelerate training.
Spot Instances:
Utilize spot instances or preemptible VMs to reduce costs for non-time-sensitive tasks.
Optimize Model Training:
Hyperparameter Tuning:
Use cloud-based hyperparameter tuning services to automate the search for optimal model parameters. Services like Google Cloud AI Platform’s HyperTune or AWS SageMaker’s Automatic Model Tuning can help.
Distributed Training:
Distribute model training across multiple instances or nodes to speed up the process. Frameworks like TensorFlow and PyTorch support distributed training and can take advantage of cloud resources.
Monitoring and Logging:
Monitoring Tools:
Implement monitoring tools to track performance metrics and resource usage. AWS CloudWatch, Google Cloud Monitoring, and Azure Monitor offer real-time insights.
Logging:
Maintain detailed logs for debugging and performance analysis, using tools like AWS CloudTrail or Google Cloud Logging.
Model Deployment:
Serverless Deployment:
Use serverless options to simplify scaling and reduce infrastructure management. Services like AWS Lambda or Google Cloud Functions can handle inference tasks without managing servers.
Model Optimization:
Optimize models by compressing them or using model distillation techniques to reduce inference time and improve latency.
Cost Management:
Cost Analysis:
Regularly analyze and optimize cloud costs to avoid overspending. Tools like AWS Cost Explorer, Google Cloud’s Cost Management, and Azure Cost Management can help monitor and manage expenses.
By carefully selecting cloud services, optimizing data handling and training processes, and monitoring performance, you can efficiently manage and improve machine learning models in the cloud.
2 notes
·
View notes
Text
Architecting for AI- Effective Data Management Strategies in the Cloud
What good is AI if the data feeding it is disorganized, outdated, or locked away in silos?
How can businesses unlock the full potential of AI in the cloud without first mastering the way they handle data?
And for professionals, how can developing Cloud AI skills shape a successful AI cloud career path?
These are some real questions organizations and tech professionals ask every day. As the push toward automation and intelligent systems grows, the spotlight shifts to where it all begins, data. If you’re aiming to become an AI cloud expert, mastering data management in the cloud is non-negotiable.
In this blog, we will explore human-friendly yet powerful strategies for managing data in cloud environments. These are perfect for businesses implementing AI in the cloud and individuals pursuing AI Cloud Certification.
1. Centralize Your Data, But Don’t Sacrifice Control
The first step to architecting effective AI systems is ensuring your data is all in one place, but with rules in place. Cloud AI skills come into play when configuring secure, centralized data lakes using platforms like AWS S3, Azure Data Lake, or Google Cloud Storage.
For instance, Airbnb streamlined its AI pipelines by unifying data into Amazon S3 while applying strict governance with AWS Lake Formation. This helped their teams quickly build and train models for pricing and fraud detection, without dealing with messy, inconsistent data.
Pro Tip-
Centralize your data, but always pair it with metadata tagging, cataloging, and access controls. This is a must-learn in any solid AI cloud automation training program.
2. Design For Scale: Elasticity Over Capacity
AI workloads are not static—they scale unpredictably. Cloud platforms shine when it comes to elasticity, enabling dynamic resource allocation as your needs grow. Knowing how to build scalable pipelines is a core part of AI cloud architecture certification programs.
One such example is Netflix. It handles petabytes of viewing data daily and processes it through Apache Spark on Amazon EMR. With this setup, they dynamically scale compute power depending on the workload, powering AI-based recommendations and content optimization.
Human Insight-
Scalability is not just about performance. It’s about not overspending. Smart scaling = cost-effective AI.
3. Don’t Just Store—Catalog Everything
You can’t trust what you can’t trace. A reliable data catalog and lineage system ensures AI models are trained on trustworthy data. Tools like AWS Glue or Apache Atlas help track data origin, movement, and transformation—a key concept for anyone serious about AI in the cloud.
To give you an example, Capital One uses data lineage tools to manage regulatory compliance for its AI models in credit risk and fraud detection. Every data point can be traced, ensuring trust in both model outputs and audits.
Why it matters-
Lineage builds confidence. Whether you’re a company building AI or a professional on an AI cloud career path, transparency is essential.
4. Build for Real-Time Intelligence
The future of AI is real-time. Whether it’s fraud detection, customer personalization, or predictive maintenance, organizations need pipelines that handle data as it flows in. Streaming platforms like Apache Kafka and AWS Kinesis are core technologies for this.
For example, Uber’s Michelangelo platform processes real-time location and demand data to adjust pricing and ETA predictions dynamically. Their cloud-native streaming architecture supports instant decision-making at scale.
Career Tip-
Mastering stream processing is key if you want to become an AI cloud expert. It’s the difference between reactive and proactive AI.
5. Bake Security and Privacy into Your Data Strategy
When you’re working with personal data, security isn’t optional—it’s foundational. AI architectures in the cloud must comply with GDPR, HIPAA, and other regulations, while also protecting sensitive information using encryption, masking, and access controls.
Salesforce, with its AI-powered Einstein platform, ensures sensitive customer data is encrypted and tightly controlled using AWS Key Management and IAM policies.
Best Practice-
Think “privacy by design.” This is a hot topic covered in depth during any reputable AI Cloud certification.
6. Use Tiered Storage to Optimize Cost and Speed
Not every byte of data is mission-critical. Some data is hot (frequently used), some cold (archived). An effective AI cloud architecture balances cost and speed with a multi-tiered storage strategy.
For instance, Pinterest uses Amazon S3 for high-access data, Glacier for archival, and caching layers for low-latency AI-powered recommendations. This approach keeps costs down while delivering fast, accurate results.
Learning Tip-
This is exactly the kind of cost-smart design covered in AI cloud automation training courses.
7. Support Cross-Cloud and Hybrid Access
Modern enterprises often operate across multiple cloud environments, and data can’t live in isolation. Cloud data architectures should support hybrid and multi-cloud scenarios to avoid vendor lock-in and enable agility.
Johnson & Johnson uses BigQuery Omni to analyze data across AWS and Azure without moving it. This federated approach supports AI use cases in healthcare, ensuring data residency and compliance.
Why it matters?
The future of AI is multi-cloud. Want to stand out? Pursue an AI cloud architecture certification that teaches integration, not just implementation.
Wrapping Up- Your Data Is the AI Foundation
Without well-architected data strategies, AI can’t perform at its best. If you’re leading cloud strategy as a CTO or just starting your journey to become an AI cloud expert, one thing becomes clear early on—solid data management isn’t optional. It’s the foundation that supports everything from smarter models to reliable performance. Without it, even the best AI tools fall short.
Here’s what to focus on-
Centralize data with control
Scale infrastructure on demand
Track data lineage and quality
Enable real-time processing
Secure data end-to-end
Store wisely with tiered solutions
Built for hybrid, cross-cloud access
Ready To Take the Next Step?
If you are looking forward to building smarter systems or your career, now is the time to invest in the future. Consider pursuing an AI Cloud Certification or an AI Cloud Architecture Certification. These credentials not only boost your knowledge but also unlock new opportunities on your AI cloud career path.
Consider checking AI CERTs AI+ Cloud Certification to gain in-demand Cloud AI skills, fast-track your AI cloud career path, and become an AI cloud expert trusted by leading organizations. With the right Cloud AI skills, you won’t just adapt to the future—you’ll shape it.
Enroll today!
0 notes
Text
Building a Smarter Netflix Clone: Personalized UX with Machine Learning
In today’s saturated streaming landscape, personalization has become the differentiator that defines user satisfaction, engagement, and retention. While content is still king, experience is the new emperor—and machine learning (ML) is its loyal architect.
Netflix, the global leader in OTT services, has set a new benchmark by leveraging data-driven intelligence to offer hyper-personalized viewing experiences. For startups and entrepreneurs aspiring to build a Netflix clone, merely replicating its content delivery system is no longer enough. Instead, the focus must shift toward smart, adaptive user experiences built on machine learning algorithms.
This essay explores how to infuse ML into your Netflix clone to deliver personalized UX and competitive edge—and why doing so is no longer optional but essential.
Why Personalization Matters in OTT Platforms
Traditional video streaming apps serve identical content to all users. However, as user expectations evolve, generic interfaces and recommendations no longer suffice. Personalization ensures that:
Viewers spend more time on the platform.
Retention and loyalty increase.
Content discovery improves, reducing churn.
ARPU (Average Revenue Per User) rises with targeted upselling.
In short, personalization makes your app feel like it knows the user—what they like, when they watch, and what they’ll want next.
How Machine Learning Powers Personalized UX
1. User Behavior Tracking
ML begins with data. Every click, watch, pause, rewind, and search becomes a data point. ML models analyze:
Viewing time per genre.
Completion rates of episodes.
Interaction with thumbnails.
Time-of-day usage patterns.
This allows the system to generate behavioral profiles in real time.
2. Recommendation Engines
Perhaps the most visible use of ML in a Netflix clone, recommendation systems can be built using:
Collaborative Filtering: Suggests content based on what similar users liked.
Content-Based Filtering: Recommends similar titles based on the user’s history.
Hybrid Models: Combines both approaches for greater accuracy.
Netflix attributes over 80% of its views to ML-powered recommendations. Clone apps must aim for the same depth of insight.
3. Smart Thumbnails & Previews
Machine learning can also select the most effective thumbnail or preview snippet for each user. Netflix runs A/B tests at scale to evaluate which images result in the highest click-through rate—often personalized per user.
OTT clone apps can automate this with ML tools that analyze:
Engagement metrics for each thumbnail.
Facial expression or color intensity.
Historical response patterns of the user.
4. Adaptive Bitrate Streaming
Using real-time ML predictions, clone apps can optimize streaming quality based on:
Internet bandwidth.
Device capacity.
Viewing environment (e.g., mobile vs. smart TV).
This improves UX significantly by minimizing buffering and enhancing video clarity without manual toggling.
5. Personalized Notifications
ML can predict the best time and most relevant reason to re-engage a user:
“New thriller from your favorite actor just dropped.”
“Continue watching your drama before bedtime?”
“Weekend binge suggestions for you.”
These nudges feel less like spam and more like intelligent reminders, thanks to predictive modeling.
Steps to Implement ML in Your Netflix Clone
Step 1: Build a Solid Data Pipeline
Before ML, you need robust data collection. Implement event tracking for:
Page visits
Play/pause/skip actions
Rating or likes
Watchlist additions
Tools like Firebase, Mixpanel, or custom backends with Kafka or Snowflake can serve as a solid foundation.
Step 2: Choose the Right ML Framework
Popular ML frameworks suitable for OTT applications:
TensorFlow / PyTorch: For building custom deep learning models.
Apache Mahout: For recommendation engines.
Amazon Personalize: AWS’s plug-and-play ML personalization tool.
Integrate these with your backend to serve real-time personalized content.
Step 3: Deploy Recommendation APIs
Make your ML models accessible via REST APIs or GraphQL. These APIs will:
Accept user ID or session data.
Return a ranked list of recommended videos or thumbnails.
Update in real time based on interaction.
Step 4: Monitor, Evaluate, and Retrain
ML is never one-and-done. Continually evaluate:
Accuracy of recommendations (using metrics like Precision, Recall, NDCG).
Engagement metrics before and after ML personalization.
Drop-off rates and churn patterns.
Use A/B testing and feedback loops to continuously improve.
Real-World Success Examples
Netflix: Claims a $1 billion/year savings through reduced churn thanks to ML-powered personalization.
YouTube: Uses deep neural networks for personalized video ranking and dramatically boosts session time.
HBO Max & Disney+: Are investing in hybrid ML systems to drive engagement.
These platforms illustrate how crucial intelligent personalization is to the survival and success of any OTT business.
Challenges in ML Personalization
Data privacy & GDPR compliance: Handle user data ethically.
Cold start problem: Hard to recommend when the user is new.
High computation costs: ML infrastructure can be resource-intensive.
Bias in algorithms: Without checks, ML can reinforce narrow content bubbles.
Overcoming these requires thoughtful design, ethical AI practices, and performance optimization.
Conclusion: Why Choose Miracuves for Your Netflix Clone with ML Integration
Building a Netflix clone business model that merely streams content is yesterday’s game. The real challenge is delivering an intelligent, personalized, data-driven user experience that evolves with every click.
This is where Miracuves comes in.
At Miracuves, we go beyond standard clone scripts. Our team integrates advanced machine learning algorithms, ensures seamless user tracking, and deploys real-time personalization models tailored to your platform’s goals. Whether you're targeting a niche genre, a regional audience, or aiming to disrupt a global market, our experts can help you build a future-ready OTT solution.
With proven experience in custom OTT app development, scalable infrastructure, and ML-backed feature sets, Miracuves is your ideal partner to build a smarter Netflix clone—not just another copy, but a competitive powerhouse.
Ready to build a Netflix Clone that truly knows your users? Let Miracuves take you there.
0 notes
Text
Top Trends Shaping the Future of Data Engineering Consultancy
In today’s digital-first world, businesses are rapidly recognizing the need for structured and strategic data management. As a result, Data Engineering Consultancy is evolving at an unprecedented pace. From cloud-native architecture to AI-driven automation, the future of data engineering is being defined by innovation and agility. Here are the top trends shaping this transformation.

1. Cloud-First Data Architectures
Modern businesses are migrating their infrastructure to cloud platforms like AWS, Azure, and Google Cloud. Data engineering consultants are now focusing on building scalable, cloud-native data pipelines that offer better performance, security, and flexibility.
2. Real-Time Data Processing
The demand for real-time analytics is growing, especially in sectors like finance, retail, and logistics. Data Engineering Consultancy services are increasingly incorporating technologies like Apache Kafka, Flink, and Spark to support instant data processing and decision-making.
3. Advanced Data Planning
A strategic approach to Data Planning is becoming central to successful consultancy. Businesses want to go beyond reactive reporting—they seek proactive, long-term strategies for data governance, compliance, and scalability.
4. Automation and AI Integration
Automation tools and AI models are revolutionizing how data is processed, cleaned, and analyzed. Data engineers now use machine learning to optimize data quality checks, ETL processes, and anomaly detection.
5. Data Democratization
Consultants are focusing on creating accessible data systems, allowing non-technical users to engage with data through intuitive dashboards and self-service analytics.
In summary, the future of Data Engineering Consultancy lies in its ability to adapt to technological advancements while maintaining a strong foundation in Data Planning. By embracing these trends, businesses can unlock deeper insights, enhance operational efficiency, and stay ahead of the competition in the data-driven era. Get in touch with Kaliper.io today!
0 notes
Link
0 notes
Text
Basil Faruqui, BMC Software: How to nail your data and AI strategy - AI News
New Post has been published on https://thedigitalinsider.com/basil-faruqui-bmc-software-how-to-nail-your-data-and-ai-strategy-ai-news/
Basil Faruqui, BMC Software: How to nail your data and AI strategy - AI News
.pp-multiple-authors-boxes-wrapper display:none; img width:100%;
BMC Software’s director of solutions marketing, Basil Faruqui, discusses the importance of DataOps, data orchestration, and the role of AI in optimising complex workflow automation for business success.
What have been the latest developments at BMC?
It’s exciting times at BMC and particularly our Control-M product line, as we are continuing to help some of the largest companies around the world in automating and orchestrating business outcomes that are dependent on complex workflows. A big focus of our strategy has been on DataOps specifically on orchestration within the DataOps practice. During the last twelve months we have delivered over seventy integrations to serverless and PaaS offerings across AWS, Azure and GCP enabling our customers to rapidly bring modern cloud services into their Control-M orchestration patterns. Plus, we are prototyping GenAI based use cases to accelerate workflow development and run-time optimisation.
What are the latest trends you’ve noticed developing in DataOps?
What we are seeing in the Data world in general is continued investment in data and analytics software. Analysts estimate that the spend on Data and Analytics software last year was in the $100 billion plus range. If we look at the Machine Learning, Artificial Intelligence & Data Landscape that Matt Turck at Firstmark publishes every year, its more crowded than ever before. It has 2,011 logos and over five hundred were added since 2023. Given this rapid growth of tools and investment, DataOps is now taking center stage as companies are realising that to successfully operationalise data initiatives, they can no longer just add more engineers. DataOps practices are now becoming the blueprint for scaling these initiatives in production. The recent boom of GenAI is going make this operational model even more important.
What should companies be mindful of when trying to create a data strategy?
As I mentioned earlier that the investment in data initiatives from business executives, CEOs, CMOs, CFOs etc. continues to be strong. This investment is not just for creating incremental efficiencies but for game changing, transformational business outcomes as well. This means that three things become very important. First is clear alignment of the data strategy with the business goals, making sure the technology teams are working on what matters the most to the business. Second, is data quality and accessibility, the quality of the data is critical. Poor data quality will lead to inaccurate insights. Equally important is ensuring data accessibility – making the right data available to the right people at the right time. Democratising data access, while maintaining appropriate controls, empowers teams across the organisation to make data-driven decisions. Third is achieving scale in production. The strategy must ensure that Ops readiness is baked into the data engineering practices so its not something that gets considered after piloting only.
How important is data orchestration as part of a company’s overall strategy?
Data Orchestration is arguably the most important pillar of DataOps. Most organisations have data spread across multiple systems – cloud, on-premises, legacy databases, and third-party applications. The ability to integrate and orchestrate these disparate data sources into a unified system is critical. Proper data orchestration ensures seamless data flow between systems, minimising duplication, latency, and bottlenecks, while supporting timely decision-making.
What do your customers tell you are their biggest difficulties when it comes to data orchestration?
Organisations continue to face the challenge of delivering data products fast and then scaling quickly in production. GenAI is a good example of this. CEOs and boards around the world are asking for quick results as they sense that this could majorly disrupt those who cannot harness its power. GenAI is mainstreaming practices such as prompt engineering, prompt chaining etc. The challenge is how do we take LLMs and vector databases, bots etc and fit them into the larger data pipeline which traverses a very hybrid architecture from multiple-clouds to on-prem including mainframes for many. This just reiterates the need for a strategic approach to orchestration which would allow folding new technologies and practices for scalable automation of data pipelines. One customer described Control-M as a power strip of orchestration where they can plug in new technologies and patterns as they emerge without having to rewire every time they swap older technologies for newer ones.
What are your top tips for ensuring optimum data orchestration?
There can be a number of top tips but I will focus on one, interoperability between application and data workflows which I believe is critical for achieving scale and speed in production. Orchestrating data pipelines is important, but it is vital to keep in mind that these pipelines are part of a larger ecosystem in the enterprise. Let’s consider an ML pipeline is deployed to predict the customers that are likely to switch to a competitor. The data that comes into such a pipeline is a result of workflows that ran in the ERP/CRM and combination of other applications. Successful completion of the application workflows is often a pre-requisite to triggering the data workflows. Once the model identifies customers that are likely to switch, the next step perhaps is to send them a promotional offer which means that we will need to go back to the application layer in the ERP and CRM. Control-M is uniquely positioned to solve this challenge as our customers use it to orchestrate and manage intricate dependencies between the application and the data layer.
What do you see as being the main opportunities and challenges when deploying AI?
AI and specifically GenAI is rapidly increasing the technologies involved in the data ecosystem. Lots of new models, vector databases and new automation patterns around prompt chaining etc. This challenge is not new to the data world, but the pace of change is picking up. From an orchestration perspective we see tremendous opportunities with our customers because we offer a highly adaptable platform for orchestration where they can fold these tools and patterns into their existing workflows versus going back to drawing board.
Do you have any case studies you could share with us of companies successfully utilising AI?
Domino’s Pizza leverages Control-M for orchestrating its vast and complex data pipelines. With over 20,000 stores globally, Domino’s manages more than 3,000 data pipelines that funnel data from diverse sources such as internal supply chain systems, sales data, and third-party integrations. This data from applications needs to go through complex transformation patterns and models before its available for driving decisions related to food quality, customer satisfaction, and operational efficiency across its franchise network.
Control-M plays a crucial role in orchestrating these data workflows, ensuring seamless integration across a wide range of technologies like MicroStrategy, AMQ, Apache Kafka, Confluent, GreenPlum, Couchbase, Talend, SQL Server, and Power BI, to name a few.
Beyond just connecting complex orchestration patterns together Control-M provides them with end-to-end visibility of pipelines, ensuring that they meet strict service-level agreements (SLAs) while handling increasing data volumes. Control-M is helping them generate critical reports faster, deliver insights to franchisees, and scale the roll out new business services.
What can we expect from BMC in the year ahead?
Our strategy for Control-M at BMC will stay focused on a couple of basic principles:
Continue to allow our customers to use Control-M as a single point of control for orchestration as they onboard modern technologies, particularly on the public cloud. This means we will continue to provide new integrations to all major public cloud providers to ensure they can use Control-M to orchestrate workflows across three major cloud infrastructure models of IaaS, Containers and PaaS (Serverless Cloud Services). We plan to continue our strong focus on serverless, and you will see more out-of-the-box integrations from Control-M to support the PaaS model.
We recognise that enterprise orchestration is a team sport, which involves coordination across engineering, operations and business users. And, with this in mind, we plan to bring a user experience and interface that is persona based so that collaboration is frictionless.
Specifically, within DataOps we are looking at the intersection of orchestration and data quality with a specific focus on making data quality a first-class citizen within application and data workflows. Stay tuned for more on this front!
Want to learn more about AI and big data from industry leaders? Check out AI & Big Data Expo taking place in Amsterdam, California, and London. The comprehensive event is co-located with other leading events including Intelligent Automation Conference, BlockX, Digital Transformation Week, and Cyber Security & Cloud Expo.
Explore other upcoming enterprise technology events and webinars powered by TechForge here.
Tags: automation, BMC, data orchestration, DataOps
#000#2023#Accessibility#ADD#ai#ai & big data expo#ai news#AI strategy#amp#Analytics#Apache#apache kafka#application layer#applications#approach#architecture#artificial#Artificial Intelligence#automation#AWS#azure#bi#Big Data#billion#BMC#board#boards#bots#box#Business
0 notes
Text
Deployment of AI/ML Models for Predictive Analytics in Real-time Environments

In today’s data-driven world, businesses across industries are leveraging artificial intelligence (AI) and machine learning (ML) to gain actionable insights and stay ahead of the curve. One of the most impactful applications of AI/ML is predictive analytics in real-time environments, enabling organizations to anticipate trends, optimize operations, and enhance decision-making. At Globose Technology Solutions Private Limited (GTS), we specialize in deploying AI/ML models that deliver real-time predictive analytics, empowering businesses to thrive in dynamic settings. In this blog, we’ll explore the importance of real-time predictive analytics, the challenges of deployment, and how GTS helps clients achieve seamless integration.
The Power of Real-Time Predictive Analytics
Predictive analytics uses historical and real-time data to forecast future outcomes, helping businesses make proactive decisions. When powered by AI/ML models in real-time environments, its potential multiplies. For example, in e-commerce, real-time predictive analytics can recommend products to customers as they browse, increasing conversion rates. In manufacturing, it can predict equipment failures before they occur, minimizing downtime. In finance, it can detect fraudulent transactions as they happen, enhancing security.
The key advantage of real-time deployment is immediacy—predictions are made on the fly, allowing businesses to respond instantly to changing conditions. This capability is critical in fast-paced industries where delays can lead to missed opportunities or costly errors.
Challenges in Deploying AI/ML Models for Real-Time Environments
While the benefits are clear, deploying AI/ML models for real-time predictive analytics comes with challenges:
Data Processing Speed: Real-time environments require models to process massive volumes of data with minimal latency. This demands robust infrastructure and efficient algorithms.
Scalability: As user demand fluctuates, models must scale seamlessly to handle increased workloads without compromising performance.
Model Accuracy and Drift: Over time, models can experience “drift” as data patterns change, leading to inaccurate predictions. Continuous monitoring and retraining are essential.
Integration with Existing Systems: Deploying AI/ML models often involves integrating them with legacy systems, which can be complex and time-consuming.
Security and Compliance: Real-time systems often handle sensitive data, requiring strict adherence to regulations like GDPR and robust security measures to prevent breaches.
At GTS, we address these challenges with a comprehensive approach to deployment, ensuring our clients’ AI/ML models perform reliably in real-time settings. Discover how we’ve tackled these challenges for our clients.
How GTS Deploys AI/ML Models for Real-Time Predictive Analytics
GTS combines technical expertise with a client-centric approach to deliver seamless AI/ML model deployments. Here’s our process:
Infrastructure Setup: We leverage cloud platforms like AWS, Azure, or Google Cloud to build scalable, low-latency environments. Tools like Kubernetes enable efficient containerization and orchestration, ensuring models can handle high data throughput.
Model Optimization: We optimize models for speed and accuracy using techniques like model pruning, quantization, and edge computing. For instance, deploying models on edge devices can reduce latency for applications like real-time fraud detection.
Real-Time Data Pipelines: We design data pipelines using technologies like Apache Kafka or Spark Streaming to process and feed data into models in real time, ensuring predictions are based on the latest information.
Monitoring and Maintenance: Post-deployment, we implement monitoring systems to track model performance and detect drift. Automated retraining pipelines ensure models remain accurate as data evolves.
Secure Integration: Our team ensures models integrate smoothly with existing systems while maintaining security. We use encryption, API authentication, and blockchain-based solutions where applicable to safeguard data.
Testing and QA: Before going live, we rigorously test models in simulated real-time environments to ensure reliability and performance under various conditions.
Learn more about our successful deployments and see how GTS has helped businesses harness the power of predictive analytics.
Real-World Applications
Imagine a logistics company using real-time predictive analytics to optimize delivery routes. GTS deploys an AI model that analyzes traffic data, weather conditions, and delivery schedules to predict the fastest routes, reducing fuel costs and improving efficiency. In healthcare, our deployed models can predict patient deterioration in real time by analyzing vital signs, enabling timely interventions. These applications demonstrate the transformative impact of real-time AI/ML deployments.
Why Choose GTS?
With over a decade of experience and a trusted client base of 500+ companies, GTS is a leader in AI/ML deployment for predictive analytics. Our full stack development, data management, and deployment expertise ensure your models deliver real-time insights that drive business success. Whether you’re in e-commerce, manufacturing, or healthcare, we tailor our solutions to meet your unique needs.
Ready to unlock the potential of real-time predictive analytics? Contact us at [email protected] to discuss your project. Explore our case studies on AI/ML deployment and let’s build a smarter future together.
0 notes
Text
Empowering Businesses with Advanced Data Engineering Solutions in Toronto – C Data Insights
In a rapidly digitizing world, companies are swimming in data—but only a few truly know how to harness it. At C Data Insights, we bridge that gap by delivering top-tier data engineering solutions in Toronto designed to transform your raw data into actionable insights. From building robust data pipelines to enabling intelligent machine learning applications, we are your trusted partner in the Greater Toronto Area (GTA).
What Is Data Engineering and Why Is It Critical?
Data engineering involves the design, construction, and maintenance of scalable systems for collecting, storing, and analyzing data. In the modern business landscape, it forms the backbone of decision-making, automation, and strategic planning.
Without a solid data infrastructure, businesses struggle with:
Inconsistent or missing data
Delayed analytics reports
Poor data quality impacting AI/ML performance
Increased operational costs
That’s where our data engineering service in GTA helps. We create a seamless flow of clean, usable, and timely data—so you can focus on growth.
Key Features of Our Data Engineering Solutions
As a leading provider of data engineering solutions in Toronto, C Data Insights offers a full suite of services tailored to your business goals:
1. Data Pipeline Development
We build automated, resilient pipelines that efficiently extract, transform, and load (ETL) data from multiple sources—be it APIs, cloud platforms, or on-premise databases.
2. Cloud-Based Architecture
Need scalable infrastructure? We design data systems on AWS, Azure, and Google Cloud, ensuring flexibility, security, and real-time access.
3. Data Warehousing & Lakehouses
Store structured and unstructured data efficiently with modern data warehousing technologies like Snowflake, BigQuery, and Databricks.
4. Batch & Streaming Data Processing
Process large volumes of data in real-time or at scheduled intervals with tools like Apache Kafka, Spark, and Airflow.
Data Engineering and Machine Learning – A Powerful Duo
Data engineering lays the groundwork, and machine learning unlocks its full potential. Our solutions enable you to go beyond dashboards and reports by integrating data engineering and machine learning into your workflow.
We help you:
Build feature stores for ML models
Automate model training with clean data
Deploy models for real-time predictions
Monitor model accuracy and performance
Whether you want to optimize your marketing spend or forecast inventory needs, we ensure your data infrastructure supports accurate, AI-powered decisions.
Serving the Greater Toronto Area with Local Expertise
As a trusted data engineering service in GTA, we take pride in supporting businesses across:
Toronto
Mississauga
Brampton
Markham
Vaughan
Richmond Hill
Scarborough
Our local presence allows us to offer faster response times, better collaboration, and solutions tailored to local business dynamics.
Why Businesses Choose C Data Insights
✔ End-to-End Support: From strategy to execution, we’re with you every step of the way ✔ Industry Experience: Proven success across retail, healthcare, finance, and logistics ✔ Scalable Systems: Our solutions grow with your business needs ✔ Innovation-Focused: We use the latest tools and best practices to keep you ahead of the curve
Take Control of Your Data Today
Don’t let disorganized or inaccessible data hold your business back. Partner with C Data Insights to unlock the full potential of your data. Whether you need help with cloud migration, real-time analytics, or data engineering and machine learning, we’re here to guide you.
📍 Proudly offering data engineering solutions in Toronto and expert data engineering service in GTA.
📞 Contact us today for a free consultation 🌐 https://cdatainsights.com
C Data Insights – Engineering Data for Smart, Scalable, and Successful Businesses
#data engineering solutions in Toronto#data engineering and machine learning#data engineering service in Gta
0 notes
Text
How Modern Data Engineering Powers Scalable, Real-Time Decision-Making
In today's world, driven by technology, businesses have evolved further and do not want to analyze data from the past. Everything from e-commerce websites providing real-time suggestions to banks verifying transactions in under a second, everything is now done in a matter of seconds. Why has this change taken place? The modern age of data engineering involves software development, data architecture, and cloud infrastructure on a scalable level. It empowers organizations to convert massive, fast-moving data streams into real-time insights.
From Batch to Real-Time: A Shift in Data Mindset
Traditional data systems relied on batch processing, in which data was collected and analyzed after certain periods of time. This led to lagging behind in a fast-paced world, as insights would be outdated and accuracy would be questionable. Ultra-fast streaming technologies such as Apache Kafka, Apache Flink, and Spark Streaming now enable engineers to create pipelines that help ingest, clean, and deliver insights in an instant. This modern-day engineering technique shifts the paradigm of outdated processes and is crucial for fast-paced companies in logistics, e-commerce, relevancy, and fintech.
Building Resilient, Scalable Data Pipelines
Modern data engineering focuses on the construction of thoroughly monitored, fault-tolerant data pipelines. These pipelines are capable of scaling effortlessly to higher volumes of data and are built to accommodate schema changes, data anomalies, and unexpected traffic spikes. Cloud-native tools like AWS Glue and Google Cloud Dataflow with Snowflake Data Sharing enable data sharing and integration scaling without limits across platforms. These tools make it possible to create unified data flows that power dashboards, alerts, and machine learning models instantaneously.
Role of Data Engineering in Real-Time Analytics
Here is where these Data Engineering Services make a difference. At this point, companies providing these services possess considerable technical expertise and can assist an organization in designing modern data architectures in modern frameworks aligned with their business objectives. From establishing real-time ETL pipelines to infrastructure handling, these services guarantee that your data stack is efficient and flexible in terms of cost. Companies can now direct their attention to new ideas and creativity rather than the endless cycle of data management patterns.
Data Quality, Observability, and Trust
Real-time decision-making depends on the quality of the data that powers it. Modern data engineering integrates practices like data observability, automated anomaly detection, and lineage tracking. These ensure that data within the systems is clean and consistent and can be traced. With tools like Great Expectations, Monte Carlo, and dbt, engineers can set up proactive alerts and validations to mitigate issues that could affect economic outcomes. This trust in data quality enables timely, precise, and reliable decisions.
The Power of Cloud-Native Architecture
Modern data engineering encompasses AWS, Azure, and Google Cloud. They provide serverless processing, autoscaling, real-time analytics tools, and other services that reduce infrastructure expenditure. Cloud-native services allow companies to perform data processing, as well as querying, on exceptionally large datasets instantly. For example, with Lambda functions, data can be transformed. With BigQuery, it can be analyzed in real-time. This allows rapid innovation, swift implementation, and significant long-term cost savings.
Strategic Impact: Driving Business Growth
Real-time data systems are providing organizations with tangible benefits such as customer engagement, operational efficiency, risk mitigation, and faster innovation cycles. To achieve these objectives, many enterprises now opt for data strategy consulting, which aligns their data initiatives to the broader business objectives. These consulting firms enable organizations to define the right KPIs, select appropriate tools, and develop a long-term roadmap to achieve desired levels of data maturity. By this, organizations can now make smarter, faster, and more confident decisions.
Conclusion
Investing in modern data engineering is more than an upgrade of technology — it's a shift towards a strategic approach of enabling agility in business processes. With the adoption of scalable architectures, stream processing, and expert services, the true value of organizational data can be attained. This ensures that whether it is customer behavior tracking, operational optimization, or trend prediction, data engineering places you a step ahead of changes before they happen, instead of just reacting to changes.
1 note
·
View note
Text
Top Australian Universities for Cloud Computing and Big Data
In the age of digital transformation, data is the new oil; cloud computing is the infrastructure fuelling its refining. Big data and cloud computing together have created a dynamic ecosystem for digital services, business intelligence, and innovation generation. As industries shift towards cloud-first policies and data-driven decision-making, the demand for qualified individuals in these areas has increased. Known for its strong academic system and industry-aligned education, Australia offers excellent opportunities for foreign students to concentrate in Cloud Computing and Big Data. This post will examine the top Australian universities leading the way in these technical domains.
Why Study Cloud Computing and Big Data in Australia?
Ranked globally, Australia's universities are well-equipped with modern research tools, industry ties, and hands-on learning environments. Here are some fascinating reasons for learning Cloud Computing and Big Data in Australia:
Global Recognition:Ranked among the top 100 globally, Australian universities offer degrees recognised all around.
Industry Integration: Courses typically include capstone projects and internships as well as research collaborations with tech behemoths such as Amazon Web Services (AWS), Google Cloud, Microsoft Azure, and IBM.
High Employability: Graduates find decent employment in sectors including government, telecommunications, healthcare, and finance.
Post-Study Work Opportunities:Australia offers post-study work visas allowing foreign graduates to gain practical experience in the country.
Core Topics Covered in Cloud Computing and Big Data Courses
Courses in these fields typically cover:
Cloud Architecture & Security
Distributed Systems & Virtualization
Big Data Analytics
Machine Learning
Data Warehousing
Cloud Services (AWS, Google Cloud, Azure)
DevOps & Infrastructure Automation
Real-Time Data Processing (Apache Spark, Kafka)
Python, R, SQL, and NoSQL Databases
Top Australian Universities for Cloud Computing and Big Data
1. University of Melbourne
The University of Melbourne offers courses such the Master of Data Science and Master of Information Technology with a Cloud Computing emphasis. Renowned for its research excellence and global standing, the university emphasises a balance between fundamental knowledge and pragmatic cloud infrastructure training. Students benefit from close relationships with industry, including projects with AWS and Google Cloud, all run from its Parkville campus in Melbourne
2. University of Sydney
Emphasising Cloud Computing and Data Management, the University of Sydney provides the Master of Data Science and the Master of Information Technology. Its comprehensive course provides students information in data mining, architecture, and analytics. Internships and cooperative research in the heart of Sydney's Camperdown campus supported by the Sydney Informatics Hub allow students to engage with industry.
3. Monash University
Monash University offers a Master of Data Science as well as a Master of Information Technology concentrating in Enterprise Systems and Cloud Computing. Known for its multidisciplinary and practical approach, Monash mixes cloud concepts with artificial intelligence, cybersecurity, and IoT. Students located at the Melbourne Clayton campus have access to modern laboratories and industry-aligned projects.
4. University of New South Wales (UNSW Sydney)
University of New South Wales (UNSW Sydney) students can choose either the Master of Data Science and Decisions or the Master of IT. Under a curriculum covering distributed systems, networking, and scalable data services, UNSW provides practical training and close ties with Microsoft, Oracle, and other world players. The Kensington campus keeps a vibrant tech learning environment.
5. Australian National University (ANU)
The Australian National University (ANU), based in Canberra, offers the Master of Computing and the Master of Machine Learning and Computer Vision, both addressing Big Data and cloud tech. ANU's strength lies in its research-driven approach and integration of data analysis into scientific and governmental applications. Its Acton campus promotes high-level research with a global vi
6. University of Queensland (UQ)
The University of Queensland (UQ) offers the Master of Data Science as well as the Master of Computer Science with a concentration in Cloud and Systems Programming. UQ's courses are meant to include large-scale data processing, cloud services, and analytics. The St. Lucia campus in Brisbane also features innovation centres and startup incubators to enable students develop useful ideas.
7. RMIT University
RMIT University provides the Master of Data Science and the Master of IT with Cloud and Mobile Computing as a specialisation. RMIT, an AWS Academy member, places great importance on applied learning and digital transformation and provides cloud certifications in its courses. Students learn in a business-like environment at the centrally located Melbourne City campus.
8. University of Technology Sydney (UTS)
University of Technology Sydney (UTS) sets itself apart with its Master of Data Science and Innovation and Master of IT with Cloud Computing specialisation. At UTS, design thinking and data visualisation receive significant attention. Located in Ultimo, Sydney, the university features a "Data Arena" allowing students to interact with big-scale data sets visually and intuitively.
9. Deakin University
Deakin University offers a Master of Data Science as well as a Master of Information Technology with Cloud and Mobile Computing. Deakin's courses are flexible, allowing on-campus or online study. Its Burwood campus in Melbourne promotes cloud-based certifications and wide use of technologies including Azure and Google Cloud in course delivery.
10. Macquarie University
Macquarie University provides the Master of Data Science and the Master of IT with a Cloud Computing and Networking track. Through strong integration of cloud environments and scalable systems, the Macquarie Data Science Centre helps to foster industry cooperation. The North Ryde campus is famous for its research partnerships in smart infrastructure and public data systems.
Job Roles and Career Opportunities
Graduates from these programs can explore a wide range of roles, including:
Cloud Solutions Architect
Data Scientist
Cloud DevOps Engineer
Big Data Analyst
Machine Learning Engineer
Cloud Security Consultant
Database Administrator (Cloud-based)
AI & Analytics Consultant
Top Recruiters in Australia:
Amazon Web Services (AWS)
Microsoft Azure
Google Cloud
IBM
Atlassian
Accenture
Commonwealth Bank of Australia
Deloitte and PwC
Entry Requirements and Application Process
While specifics vary by university, here are the general requirements:
Academic Qualification: Bachelor’s degree in IT, Computer Science, Engineering, or a related field.
English Proficiency: IELTS (6.5 or above), TOEFL, or PTE.
Prerequisites:Some courses might need knowledge of statistics or programming (Python, Java).
Documents NeededSOP, academic transcripts, CV, current passport, and letters of recommendation.
Intakes:
February and July are the most common intakes.
Final Thoughts
Given the growing global reliance on digital infrastructure and smart data, jobs in Cloud Computing and Big Data are not only in demand but also absolutely essential. Australian universities are driving this transformation by offering overseas students the chance to learn from the best, interact with real-world technologies, and boldly enter global tech roles. From immersive courses and knowledgeable professors to strong industry ties, Australia provides the ideal launchpad for future-ready tech professionals.
Clifton Study Abroad is an authority in helping students like you negotiate the challenging road of overseas education. Our experienced advisors are here to help you at every turn, from choosing the right university to application preparation to getting a student visa. Your future in technology starts here; let us help you in opening your perfect Cloud Computing and Big Data job.
Are you looking for the best study abroad consultants in Kochi
#study abroad#study in uk#study abroad consultants#study in australia#study in germany#study in ireland#study blog
0 notes
Text
InsightGen AI Services by Appit: Unlock Real-Time Business Intelligence
Redefining Data-Driven Decision Making in the AI Era
In today’s hyperconnected and competitive environment, businesses can no longer rely on static reports or delayed analytics. The need for real-time insights, predictive intelligence, and data democratization is more critical than ever. Enter InsightGen AI Services by Appit—a cutting-edge solution designed to empower organizations with instant, actionable business intelligence powered by artificial intelligence and machine learning.
With InsightGen, Appit is revolutionizing how businesses understand data, forecast outcomes, and make mission-critical decisions—in real time.
What Is InsightGen AI?
InsightGen AI is a next-gen platform developed by Appit that enables businesses to extract deeper, smarter, and faster insights from structured and unstructured data. Unlike traditional BI tools, InsightGen combines AI-driven analytics, real-time data processing, and intuitive visualization dashboards to give decision-makers an always-on, intelligent pulse of their organization.
🧠 Core Capabilities:
Real-time analytics and dashboards
Predictive modeling and forecasting
Natural language query interface (NLQ)
AI-powered anomaly detection
Automated data storytelling and alerts
Integration with ERPs, CRMs, data lakes & cloud platforms
Why InsightGen Matters in 2025 and Beyond
⏱️ Real-Time Decision Making
In a world where trends shift by the minute, InsightGen enables organizations to act on data as it happens, not after it’s too late.
🔮 Predict the Future with Confidence
With built-in ML models, users can accurately forecast sales, churn, demand, and risk, allowing leadership to prepare for future scenarios with data-backed confidence.
🌐 Unify Data Across Sources
From siloed systems to cloud-native environments, InsightGen ingests data from various sources—SAP, Oracle, Salesforce, AWS, Azure, and more—to present a single source of truth.
💬 Ask Questions in Plain English
With Natural Language Query capabilities, even non-technical users can ask questions like "What was our top-selling product last quarter?" and receive instant visual answers.
🔔 Instant Alerts and Automation
InsightGen detects outliers, anomalies, and trends in real-time and sends automated alerts—preventing costly delays and enabling proactive actions.
Use Cases: Driving Intelligence Across Industries
🛒 Retail & eCommerce
Track inventory and sales in real time
Analyze customer buying behavior and personalize offers
Forecast seasonal demand with AI models
🏭 Manufacturing
Monitor production KPIs in real-time
Predict equipment failure using predictive maintenance AI
Optimize supply chain operations and reduce downtime
💼 Financial Services
Real-time fraud detection and transaction monitoring
Investment performance analytics
Compliance tracking and risk forecasting
🧬 Healthcare
Patient data analysis and treatment outcome prediction
Hospital resource planning and optimization
Monitor patient flow and emergency response trends
🎓 Education
Analyze student performance and dropout risks
Real-time reporting on admissions and operations
Personalized learning analytics for better outcomes
Security, Scalability, and Compliance
Appit designed InsightGen AI with enterprise-grade architecture, offering:
🔐 Role-based access control and end-to-end encryption
☁️ Cloud, on-prem, and hybrid deployment options
📊 Support for GDPR, HIPAA, CCPA, and other data regulations
⚙️ Auto-scaling and high availability infrastructure
InsightGen ensures that your data is safe, compliant, and available—always.
The Technology Behind InsightGen AI
InsightGen is built using a powerful technology stack including:
AI/ML Engines: TensorFlow, PyTorch, Scikit-learn
Data Platforms: Apache Kafka, Snowflake, Google BigQuery, Redshift
Visualization Tools: Custom dashboards, embedded BI, Power BI integration
Integration APIs: RESTful services, JSON, XML, Webhooks
AI Assistants: Integrated chat support for querying reports and insights
Case Study: Fortune 500 Firm Unlocks $12M in Cost Savings
Client: Global logistics and warehousing company Challenge: Disconnected data systems, slow insights, reactive decision-making Solution: Appit deployed InsightGen AI with real-time inventory tracking, predictive maintenance alerts, and automated KPI reporting. Results:
📉 $12M saved in operational inefficiencies
📊 65% faster decision cycles
🔄 90% automation of manual reporting
📈 40% improvement in customer SLA compliance
Getting Started with InsightGen AI Services
Whether you're a mid-sized enterprise or a Fortune 1000 company, InsightGen is scalable to meet your analytics maturity level. Appit offers end-to-end support from:
Data strategy and planning
Deployment and integration
Custom dashboard design
AI model training and tuning
Ongoing analytics support and optimization
Why Choose Appit for AI-Powered Business Intelligence?
✅ Decade-long expertise in enterprise software and AI
✅ Tailored analytics solutions for multiple industries
✅ Fast deployment with low-code/no-code customization options
✅ 24/7 support and continuous model refinement
✅ Trusted by leading organizations worldwide
With InsightGen AI, you’re not just collecting data—you’re unlocking real-time, business-changing intelligence.
The Future Is Now: Make Smarter Decisions with InsightGen
In 2025, businesses that react fast, predict accurately, and personalize effectively will win. InsightGen AI by Appit delivers the intelligence layer your enterprise needs to stay ahead of the curve.
Don’t let your data gather dust. Activate it. Understand it. Act on it.
0 notes
Text
Accelerating Innovation with Data Engineering on AWS and Aretove’s Expertise as a Leading Data Engineering Company
In today’s digital economy, the ability to process and act on data in real-time is a significant competitive advantage. This is where Data Engineering on AWS and the support of a dedicated Data Engineering Company like Aretove come into play. These solutions form the backbone of modern analytics architectures, powering everything from real-time dashboards to machine learning pipelines.
What is Data Engineering and Why is AWS the Platform of Choice?
Data engineering is the practice of designing and building systems for collecting, storing, and analyzing data. As businesses scale, traditional infrastructures struggle to handle the volume, velocity, and variety of data. This is where Amazon Web Services (AWS) shines.
AWS offers a robust, flexible, and scalable environment ideal for modern data workloads. Aretove leverages a variety of AWS tools—like Amazon Redshift, AWS Glue, and Amazon S3—to build data pipelines that are secure, efficient, and cost-effective.
Core Benefits of AWS for Data Engineering
Scalability: AWS services automatically scale to handle growing data needs.
Flexibility: Supports both batch and real-time data processing.
Security: Industry-leading compliance and encryption capabilities.
Integration: Seamlessly works with machine learning tools and third-party apps.
At Aretove, we customize your AWS architecture to match business goals, ensuring performance without unnecessary costs.
Aretove: A Trusted Data Engineering Company
As a premier Data Engineering Aws , Aretove specializes in end-to-end solutions that unlock the full potential of your data. Whether you're migrating to the cloud, building a data lake, or setting up real-time analytics, our team of experts ensures a seamless implementation.
Our services include:
Data Pipeline Development: Build robust ETL/ELT pipelines using AWS Glue and Lambda.
Data Warehousing: Design scalable warehouses with Amazon Redshift for fast querying and analytics.
Real-time Streaming: Implement streaming data workflows with Amazon Kinesis and Apache Kafka.
Data Governance and Quality: Ensure your data is accurate, consistent, and secure.
Case Study: Real-Time Analytics for E-Commerce
An e-commerce client approached Aretove to improve its customer insights using real-time analytics. We built a cloud-native architecture on AWS using Kinesis for stream ingestion and Redshift for warehousing. This allowed the client to analyze customer behavior instantly and personalize recommendations, leading to a 30% boost in conversion rates.
Why Aretove Stands Out
What makes Aretove different is our ability to bridge business strategy with technical execution. We don’t just build pipelines—we build solutions that drive revenue, enhance user experiences, and scale with your growth.
With a client-centric approach and deep technical know-how, Aretove empowers businesses across industries to harness the power of their data.
Looking Ahead
As data continues to fuel innovation, companies that invest in modern data engineering practices will be the ones to lead. AWS provides the tools, and Aretove brings the expertise. Together, we can transform your data into a strategic asset.
Whether you’re starting your cloud journey or optimizing an existing environment, Aretove is your go-to partner for scalable, intelligent, and secure data engineering solutions.
0 notes
Text
The top Data Engineering trends to look for in 2025

Data engineering is the unsung hero of our data-driven world. It's the critical discipline that builds and maintains the robust infrastructure enabling organizations to collect, store, process, and analyze vast amounts of data. As we navigate mid-2025, this foundational field is evolving at an unprecedented pace, driven by the exponential growth of data, the insatiable demand for real-time insights, and the transformative power of AI.
Staying ahead of these shifts is no longer optional; it's essential for data engineers and the organizations they support. Let's dive into the key data engineering trends that are defining the landscape in 2025.
1. The Dominance of the Data Lakehouse
What it is: The data lakehouse architecture continues its strong upward trajectory, aiming to unify the best features of data lakes (flexible, low-cost storage for raw, diverse data types) and data warehouses (structured data management, ACID transactions, and robust governance). Why it's significant: It offers a single platform for various analytics workloads, from BI and reporting to AI and machine learning, reducing data silos, complexity, and redundancy. Open table formats like Apache Iceberg, Delta Lake, and Hudi are pivotal in enabling lakehouse capabilities. Impact: Greater data accessibility, improved data quality and reliability for analytics, simplified data architecture, and cost efficiencies. Key Technologies: Databricks, Snowflake, Amazon S3, Azure Data Lake Storage, Apache Spark, and open table formats.
2. AI-Powered Data Engineering (Including Generative AI)
What it is: Artificial intelligence, and increasingly Generative AI, are becoming integral to data engineering itself. This involves using AI/ML to automate and optimize various data engineering tasks. Why it's significant: AI can significantly boost efficiency, reduce manual effort, improve data quality, and even help generate code for data pipelines or transformations. Impact: * Automated Data Integration & Transformation: AI tools can now automate aspects of data mapping, cleansing, and pipeline optimization. * Intelligent Data Quality & Anomaly Detection: ML algorithms can proactively identify and flag data quality issues or anomalies in pipelines. * Optimized Pipeline Performance: AI can help in tuning and optimizing the performance of data workflows. * Generative AI for Code & Documentation: LLMs are being used to assist in writing SQL queries, Python scripts for ETL, and auto-generating documentation. Key Technologies: AI-driven ETL/ELT tools, MLOps frameworks integrated with DataOps, platforms with built-in AI capabilities (e.g., Databricks AI Functions, AWS DMS with GenAI).
3. Real-Time Data Processing & Streaming Analytics as the Norm
What it is: The demand for immediate insights and actions based on live data streams continues to grow. Batch processing is no longer sufficient for many use cases. Why it's significant: Businesses across industries like e-commerce, finance, IoT, and logistics require real-time capabilities for fraud detection, personalized recommendations, operational monitoring, and instant decision-making. Impact: A shift towards streaming architectures, event-driven data pipelines, and tools that can handle high-throughput, low-latency data. Key Technologies: Apache Kafka, Apache Flink, Apache Spark Streaming, Apache Pulsar, cloud-native streaming services (e.g., Amazon Kinesis, Google Cloud Dataflow, Azure Stream Analytics), and real-time analytical databases.
4. The Rise of Data Mesh & Data Fabric Architectures
What it is: * Data Mesh: A decentralized sociotechnical approach that emphasizes domain-oriented data ownership, treating data as a product, self-serve data infrastructure, and federated computational governance. * Data Fabric: An architectural approach that automates data integration and delivery across disparate data sources, often using metadata and AI to provide a unified view and access to data regardless of where it resides. Why it's significant: Traditional centralized data architectures struggle with the scale and complexity of modern data. These approaches offer greater agility, scalability, and empower domain teams. Impact: Improved data accessibility and discoverability, faster time-to-insight for domain teams, reduced bottlenecks for central data teams, and better alignment of data with business domains. Key Technologies: Data catalogs, data virtualization tools, API-based data access, and platforms supporting decentralized data management.
5. Enhanced Focus on Data Observability & Governance
What it is: * Data Observability: Going beyond traditional monitoring to provide deep visibility into the health and state of data and data pipelines. It involves tracking data lineage, quality, freshness, schema changes, and distribution. * Data Governance by Design: Integrating robust data governance, security, and compliance practices directly into the data lifecycle and infrastructure from the outset, rather than as an afterthought. Why it's significant: As data volumes and complexity grow, ensuring data quality, reliability, and compliance (e.g., GDPR, CCPA) becomes paramount for building trust and making sound decisions. Regulatory landscapes, like the EU AI Act, are also making strong governance non-negotiable. Impact: Improved data trust and reliability, faster incident resolution, better compliance, and more secure data handling. Key Technologies: AI-powered data observability platforms, data cataloging tools with governance features, automated data quality frameworks, and tools supporting data lineage.
6. Maturation of DataOps and MLOps Practices
What it is: * DataOps: Applying Agile and DevOps principles (automation, collaboration, continuous integration/continuous delivery - CI/CD) to the entire data analytics lifecycle, from data ingestion to insight delivery. * MLOps: Extending DevOps principles specifically to the machine learning lifecycle, focusing on streamlining model development, deployment, monitoring, and retraining. Why it's significant: These practices are crucial for improving the speed, quality, reliability, and efficiency of data and machine learning pipelines. Impact: Faster delivery of data products and ML models, improved data quality, enhanced collaboration between data engineers, data scientists, and IT operations, and more reliable production systems. Key Technologies: Workflow orchestration tools (e.g., Apache Airflow, Kestra), CI/CD tools (e.g., Jenkins, GitLab CI), version control systems (Git), containerization (Docker, Kubernetes), and MLOps platforms (e.g., MLflow, Kubeflow, SageMaker, Azure ML).
The Cross-Cutting Theme: Cloud-Native and Cost Optimization
Underpinning many of these trends is the continued dominance of cloud-native data engineering. Cloud platforms (AWS, Azure, GCP) provide the scalable, flexible, and managed services that are essential for modern data infrastructure. Coupled with this is an increasing focus on cloud cost optimization (FinOps for data), as organizations strive to manage and reduce the expenses associated with large-scale data processing and storage in the cloud.
The Evolving Role of the Data Engineer
These trends are reshaping the role of the data engineer. Beyond building pipelines, data engineers in 2025 are increasingly becoming architects of more intelligent, automated, and governed data systems. Skills in AI/ML, cloud platforms, real-time processing, and distributed architectures are becoming even more crucial.
Global Relevance, Local Impact
These global data engineering trends are particularly critical for rapidly developing digital economies. In countries like India, where the data explosion is immense and the drive for digital transformation is strong, adopting these advanced data engineering practices is key to harnessing data for innovation, improving operational efficiency, and building competitive advantages on a global scale.
Conclusion: Building the Future, One Pipeline at a Time
The field of data engineering is more dynamic and critical than ever. The trends of 2025 point towards more automated, real-time, governed, and AI-augmented data infrastructures. For data engineering professionals and the organizations they serve, embracing these changes means not just keeping pace, but actively shaping the future of how data powers our world.
1 note
·
View note
Text
How AI Is Revolutionizing Contact Centers in 2025
As contact centers evolve from reactive customer service hubs to proactive experience engines, artificial intelligence (AI) has emerged as the cornerstone of this transformation. In 2025, modern contact center architectures are being redefined through AI-based technologies that streamline operations, enhance customer satisfaction, and drive measurable business outcomes.
This article takes a technical deep dive into the AI-powered components transforming contact centers—from natural language models and intelligent routing to real-time analytics and automation frameworks.
1. AI Architecture in Modern Contact Centers
At the core of today’s AI-based contact centers is a modular, cloud-native architecture. This typically consists of:
NLP and ASR engines (e.g., Google Dialogflow, AWS Lex, OpenAI Whisper)
Real-time data pipelines for event streaming (e.g., Apache Kafka, Amazon Kinesis)
Machine Learning Models for intent classification, sentiment analysis, and next-best-action
RPA (Robotic Process Automation) for back-office task automation
CDP/CRM Integration to access customer profiles and journey data
Omnichannel orchestration layer that ensures consistent CX across chat, voice, email, and social
These components are containerized (via Kubernetes) and deployed via CI/CD pipelines, enabling rapid iteration and scalability.
2. Conversational AI and Natural Language Understanding
The most visible face of AI in contact centers is the conversational interface—delivered via AI-powered voice bots and chatbots.
Key Technologies:
Automatic Speech Recognition (ASR): Converts spoken input to text in real time. Example: OpenAI Whisper, Deepgram, Google Cloud Speech-to-Text.
Natural Language Understanding (NLU): Determines intent and entities from user input. Typically fine-tuned BERT or LLaMA models power these layers.
Dialog Management: Manages context-aware conversations using finite state machines or transformer-based dialog engines.
Natural Language Generation (NLG): Generates dynamic responses based on context. GPT-based models (e.g., GPT-4) are increasingly embedded for open-ended interactions.
Architecture Snapshot:
plaintext
CopyEdit
Customer Input (Voice/Text)
↓
ASR Engine (if voice)
↓
NLU Engine → Intent Classification + Entity Recognition
↓
Dialog Manager → Context State
↓
NLG Engine → Response Generation
↓
Omnichannel Delivery Layer
These AI systems are often deployed on low-latency, edge-compute infrastructure to minimize delay and improve UX.
3. AI-Augmented Agent Assist
AI doesn’t only serve customers—it empowers human agents as well.
Features:
Real-Time Transcription: Streaming STT pipelines provide transcripts as the customer speaks.
Sentiment Analysis: Transformers and CNNs trained on customer service data flag negative sentiment or stress cues.
Contextual Suggestions: Based on historical data, ML models suggest actions or FAQ snippets.
Auto-Summarization: Post-call summaries are generated using abstractive summarization models (e.g., PEGASUS, BART).
Technical Workflow:
Voice input transcribed → parsed by NLP engine
Real-time context is compared with knowledge base (vector similarity via FAISS or Pinecone)
Agent UI receives predictive suggestions via API push
4. Intelligent Call Routing and Queuing
AI-based routing uses predictive analytics and reinforcement learning (RL) to dynamically assign incoming interactions.
Routing Criteria:
Customer intent + sentiment
Agent skill level and availability
Predicted handle time (via regression models)
Customer lifetime value (CLV)
Model Stack:
Intent Detection: Multi-label classifiers (e.g., fine-tuned RoBERTa)
Queue Prediction: Time-series forecasting (e.g., Prophet, LSTM)
RL-based Routing: Models trained via Q-learning or Proximal Policy Optimization (PPO) to optimize wait time vs. resolution rate
5. Knowledge Mining and Retrieval-Augmented Generation (RAG)
Large contact centers manage thousands of documents, SOPs, and product manuals. AI facilitates rapid knowledge access through:
Vector Embedding of documents (e.g., using OpenAI, Cohere, or Hugging Face models)
Retrieval-Augmented Generation (RAG): Combines dense retrieval with LLMs for grounded responses
Semantic Search: Replaces keyword-based search with intent-aware queries
This enables agents and bots to answer complex questions with dynamic, accurate information.
6. Customer Journey Analytics and Predictive Modeling
AI enables real-time customer journey mapping and predictive support.
Key ML Models:
Churn Prediction: Gradient Boosted Trees (XGBoost, LightGBM)
Propensity Modeling: Logistic regression and deep neural networks to predict upsell potential
Anomaly Detection: Autoencoders flag unusual user behavior or possible fraud
Streaming Frameworks:
Apache Kafka / Flink / Spark Streaming for ingesting and processing customer signals (page views, clicks, call events) in real time
These insights are visualized through BI dashboards or fed back into orchestration engines to trigger proactive interventions.
7. Automation & RPA Integration
Routine post-call processes like updating CRMs, issuing refunds, or sending emails are handled via AI + RPA integration.
Tools:
UiPath, Automation Anywhere, Microsoft Power Automate
Workflows triggered via APIs or event listeners (e.g., on call disposition)
AI models can determine intent, then trigger the appropriate bot to complete the action in backend systems (ERP, CRM, databases)
8. Security, Compliance, and Ethical AI
As AI handles more sensitive data, contact centers embed security at multiple levels:
Voice biometrics for authentication (e.g., Nuance, Pindrop)
PII Redaction via entity recognition models
Audit Trails of AI decisions for compliance (especially in finance/healthcare)
Bias Monitoring Pipelines to detect model drift or demographic skew
Data governance frameworks like ISO 27001, GDPR, and SOC 2 compliance are standard in enterprise AI deployments.
Final Thoughts
AI in 2025 has moved far beyond simple automation. It now orchestrates entire contact center ecosystems—powering conversational agents, augmenting human reps, automating back-office workflows, and delivering predictive intelligence in real time.
The technical stack is increasingly cloud-native, model-driven, and infused with real-time analytics. For engineering teams, the focus is now on building scalable, secure, and ethical AI infrastructures that deliver measurable impact across customer satisfaction, cost savings, and employee productivity.
As AI models continue to advance, contact centers will evolve into fully adaptive systems, capable of learning, optimizing, and personalizing in real time. The revolution is already here—and it's deeply technical.
#AI-based contact center#conversational AI in contact centers#natural language processing (NLP)#virtual agents for customer service#real-time sentiment analysis#AI agent assist tools#speech-to-text AI#AI-powered chatbots#contact center automation#AI in customer support#omnichannel AI solutions#AI for customer experience#predictive analytics contact center#retrieval-augmented generation (RAG)#voice biometrics security#AI-powered knowledge base#machine learning contact center#robotic process automation (RPA)#AI customer journey analytics
0 notes